Is Data Mesh new Data Lake?


 According to Wikipedia, the term data mesh was first defined by Zhamak Dehghani in 2019. Compared, to the term data lake, defined in 2011 by James Dixon, data mesh can be considered novel. Don't worry if you haven't heard of it yet. When writing this article, the year 2022 comes to an end and data lakes became very popular. Big companies already have them. Some made data lakes smart, some made data lakes because there was no alternative. All the rest just waited. After 10 years of common building data lakes, I am aware enough to say, they do not fit all. Since cloud data platforms became smart, scalable, affordable, and easy to get, having them has become simple, compared to implementing data lakes in recent history. The thing is, there is no need to call our platforms data lakes anymore.
According to Wikipedia, the term data mesh was first defined by Zhamak Dehghani in 2019. Compared, to the term data lake, defined in 2011 by James Dixon, data mesh can be considered novel. Don't worry if you haven't heard of it yet. When writing this article, the year 2022 comes to an end and data lakes became very popular. Big companies already have them. Some made data lakes smart, some made data lakes because there was no alternative. All the rest just waited. After 10 years of common building data lakes, I am aware enough to say, they do not fit all. Since cloud data platforms became smart, scalable, affordable, and easy to get, having them has become simple, compared to implementing data lakes in recent history. The thing is, there is no need to call our platforms data lakes anymore.
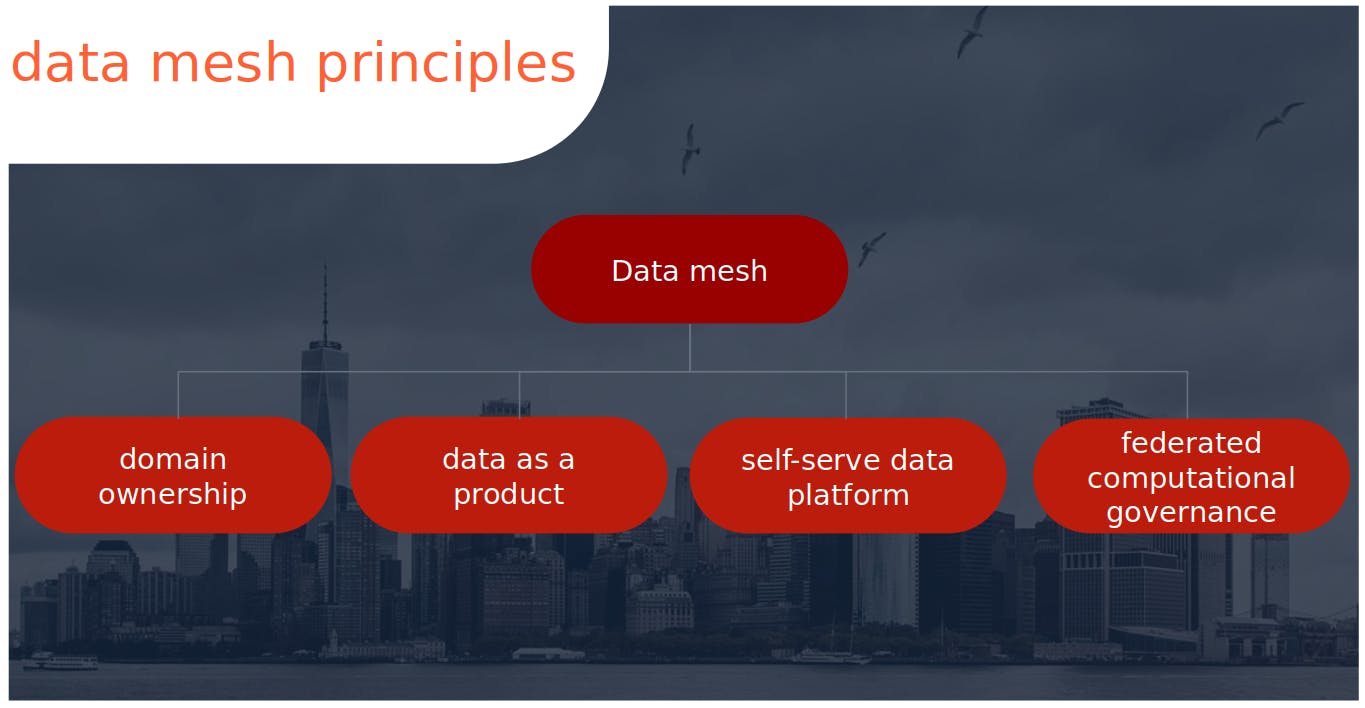
Data mesh, with decentralized data architecture, has much more in common with decentralized software architecture used by micro-services. It seems to be a better match than a monolith approach. The principals of data mesh (domain ownership, data as a product, self-serve data platform, federated computational governance) fit the micro-services architecture and handle rapidly changing data and software trends (micro-services + cloud revolution + pandemic digital revolution + what’s next?). Having in mind tough data lake implementations, building data mesh ought to be preceded by the readiness of a complete cloud platform that meets expectations and covers all data mesh principles. I am almost sure, that GCP, AWS, or Azure are currently working hard to deliver a data mesh platform before the competition does. Business awaits mature self-serve data platform not to be stuck in implementation horror like before.
Can we assume, that the data community would abandon data lakes and switch to data mesh in the nearest future instead? Too much time and money were spent on it, to just leave it behind. Data lakes will remain, but with smarter development and maintenance than nowadays. Most companies will probably draw attention to the data as a product, not a by-product. That is the main data mesh principle in my opinion.
Will data mesh solve most data-related problems? That was expected from data lakes in the past. After reading Data Mesh: Delivering Data-Driven Value at Scale I am sure no. Domain ownership, another principal of data mesh, requires rearranging the structure of the company and forces it to hand over responsibility to domain owners. Centralized teams and the decisions that come with them, are currently bottlenecks in data management. They would have to give their domains away. That doesn't come easy.

Last, but not least, we miss one principal in the data mesh list. The one which is closest to my heart. To build solutions as simple as possible. Data mesh not directly speaks of it. Centralized teams building centralized pipelines with centralized analytics on top sound slow, not agile, and not flexible enough. The federated computational governance, the last data mesh principal, federates the governance. Makes it domain-wise, with a common core on a centralized platform. This model shows, how newly created structures, pipelines, objects, and analytics should look like. Many would say, we already have that in place, but without calling it data mesh. I agree, but having in mind how cloud platforms recently reinvented the wheel, we should use them to build our data mesh smart and quickly.
After my tough experience with a data lake, I am keener to say, that I was waiting for data mesh. I am just curious, about how business, will look on it. It's exactly the opposite of what it has been doing for the last few years.