Dbt Insights



Don't expect magic from dbt and don't expect it will fix all your problems. Instead, expect to get a stable framework that makes your project as simple as possible. The only side effect of simplification I noticed is that I face much fewer problems and the ones I encounter are usually simple to debug. Bear in mind that every tool works just as smart as we allow it. The general concept of dbt is to use models, which in short, are SQL statements. Instead of using stored procedures, dynamic SQL, or Python data wrangling, dbt forces us to stick to its generic strategy. It gives us no choice, but to use it straightforwardly and organize our pipelines simply and efficiently. In the long term, this simplification brings benefits.
Let’s check, how the main dbt features work in detail. A simple example:
dbt run --profile dev --target local --model fact_events --full-refresh
10:53:35 Running with dbt=1.0.4
10:53:36 Change detected to override macro used during parsing. Starting full parse.
10:53:43 Concurrency: 1 threads (target='local')
10:53:43 1 of 1 START table model marcin.fact_events....................... [RUN]
10:53:44 1 of 1 OK created table model marcin.fact_events.................. [SELECT 0 in 0.50s]
10:53:44 Finished running 1 table model in 0.75s.
While checking logs, I found out, that there are many run arguments available. Most of the arguments use defaults.
10:53:35.805042 [debug] [MainThread]: running dbt with arguments
Namespace(record_timing_info=None, debug=None, log_format=None,
write_json=None, use_colors=None, printer_width=None, warn_error=
None, version_check=None, partial_parse=None, single_threaded=False
, use_experimental_parser=None, static_parser=None, profiles_dir=
'/home/dell/.dbt', send_anonymous_usage_stats=None, fail_fast=None,
event_buffer_size=None, project_dir=None, profile='dev', target='local',
vars='{}', log_cache_events=False, threads=None, select=['fact_events'],
exclude=None, selector_name=None, state=None, defer=None, full_refresh=
False, cls=<class 'dbt.task.run.RunTask'>, which='run', rpc_method='run')
After a successful run, let's explore logs and check how does the dbt execution sequence look like. As the first step, dbt parses Jinja macros and compiles the model.
10:53:40 [debug] [MainThread]: 1602: parser fallback to jinja rendering on marcin.fact_events.sql
Then establishes a connection.
10:53:43 [debug] [MainThread]: Acquiring new Postgres connection "master"
Then generates a list of dependencies used in orchestration. At this step, dbt verifies if we have no loops and it puts the model in the correct place in our pipeline. This is how DAG (Directed Acyclic Graph) is generated in dbt.
with relation as (
select
pg_rewrite.ev_class as class,
pg_rewrite.oid as id
from pg_rewrite
),
class as (
select
oid as id,
relname as name,
relnamespace as schema,
relkind as kind
from pg_class
),
dependency as (
select
pg_depend.objid as id,
pg_depend.refobjid as ref
from pg_depend
),
schema as (
select
pg_namespace.oid as id,
pg_namespace.nspname as name
from pg_namespace
where
pg_namespace.nspname != 'information_schema' and
pg_namespace.nspname not like 'pg\_%'
),
referenced as (
select
relation.id as id,
referenced_class.name,
referenced_class.schema,
referenced_class.kind
from relation
inner join class as referenced_class
on relation.class = referenced_class.id
where referenced_class.kind in ('r', 'v')
),
relationships as (
select
referenced.name as referenced_name,
referenced.schema as referenced_schema_id,
dependent_class.name as dependent_name,
dependent_class.schema as dependent_schema_id,
referenced.kind as kind
from referenced
inner join dependency
on referenced.id = dependency.id
inner join class as dependent_class
on dependency.ref = dependent_class.id
where
(referenced.name != dependent_class.name
or referenced.schema != dependent_class.schema)
)
select
referenced_schema.name as referenced_schema,
relationships.referenced_name as referenced_name,
dependent_schema.name as dependent_schema,
relationships.dependent_name as dependent_name
from relationships
inner join schema as dependent_schema
on relationships.dependent_schema_id = dependent_schema.id
inner join schema as referenced_schema
on relationships.referenced_schema_id = referenced_schema.id
group by
referenced_schema,
referenced_name,
dependent_schema,
dependent_name
order by
referenced_schema,
referenced_name,
dependent_schema,
dependent_name;
Then, dbt checks configurations. These may be set in the dbt_project.yml file or directly in model.sql. Dbt executes configured pre_hooks which are meant to run before model execution, although normally in the same transaction. For example, we can use pre_hooks to set the session variables:
{{
config(
alias='fact_events',
unique_key="event_id",
materialized='incremental',
pre_hook=["SET work_mem='4GB'"],
post_hook=[after_commit("
CREATE INDEX IF NOT EXISTS idx_{{ this.name }}_event_id ON {{ this }} (event_id);
")]
)
}}
Then, dbt dynamically generates and executes a sequence of dbt-generic SQLs with Jinja injections. The body defined in our model is used in the sequence, as feed. The generic SQLs are injected with it and eventually committed. Dbt uses here a common strategy with temporary objects and renaming. It increases the availability of tables, reduces locks, and provides a simple rollback when necessary. Here is the code for full-refresh. I think you have already seen something similar before.
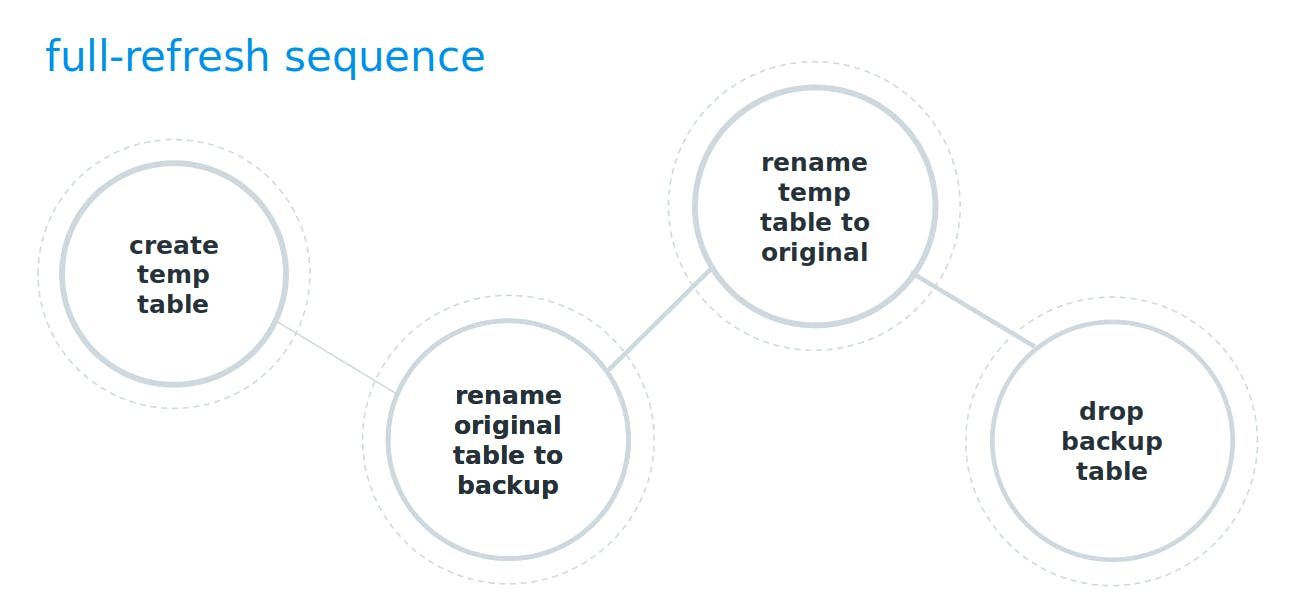
create table "marcin"."fact_events__dbt_tmp" as (SELECT …);
alter table "marcin"."fact_events" rename to "fact_events__dbt_backup";
alter table "marcin"."fact_events__dbt_tmp" rename to "fact_events;
drop table if exists "marcin"."events__dbt_backup" cascade;
commit;
In the case of incremental load, the execution sequence looks different, as we use only a slice of data. We run the examples on PostgreSQL, so below we can see the delete/insert strategy. However, the incremental strategies are database-dependent and for other database systems, we may also use the merge strategy. Increment loads are something we deal with every day in data engineering, yet here we get a generic solution that, once more, makes the project unified and easy to maintain. Moreover, porting it to a different DB backend is mostly a matter of minor configuration changes, while the model's logic remains untouched.
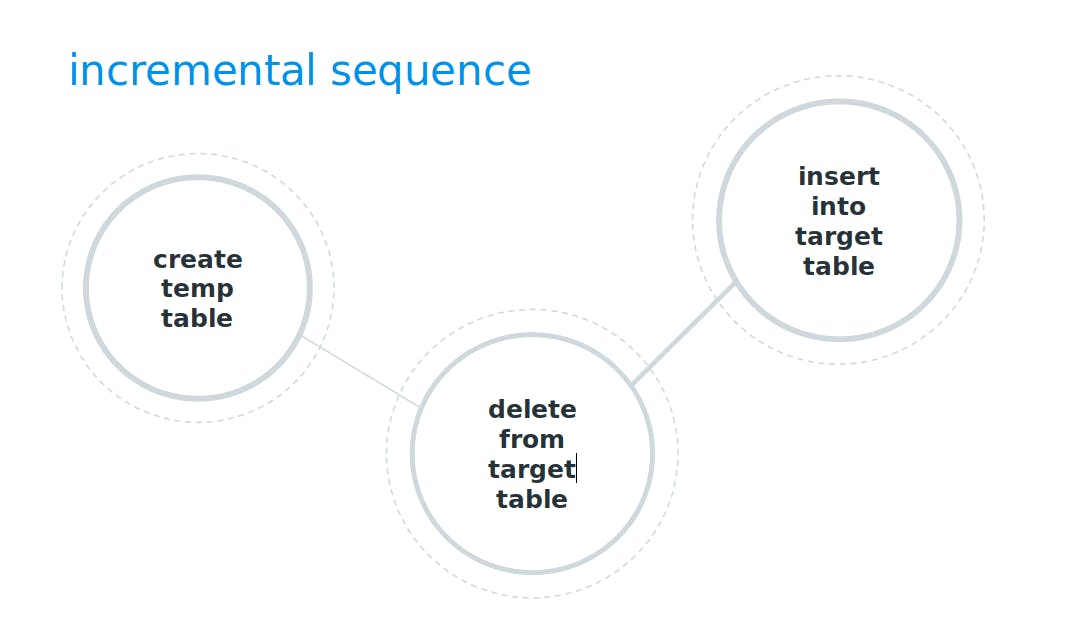
create temporary table "fact_events__dbt_tmp152147555458" as (SELECT * FROM"source"."fact_events" WHERE updated_at > (SELECT MAX(updated_at) FROM "marcin"."fact_events"));
delete from "marcin"."fact_events" where (event_id) in (select (event_id) from "fact_events__dbt_tmp152147555458");
insert into "postgres"."marcin"."fact_events" select * from "fact_events__dbt_tmp152147555458")
In the configuration block, we also defined an after_commit post_hook, which dbt executes outside the transaction. Pre_hooks and post_hooks may run within the transaction, however, in this case, we had an important reason to put one outside. Due to the fact, that all indices (created formerly) remain in the backup object until the transaction is committed, the database does not allow us to create a duplicate.
Indices have unique names within the database. It is impossible to have two indices at the same time with the same name. This is why we need to wait till the backup object(with original indices) is dropped and then proceed with new ones. That may happen only after_commit. We can see that dbt gives us a lot of flexibility in this matter. Another good example is vacuum post_hook, defined on a project level in dbt_project.yml file. In this case, we do not need to repeat the same code in every model. This is how DRY code works in dbt.
VACUUM (ANALYZE) "postgres"."marcin"."fact_events";
CREATE INDEX IF NOT EXISTS idx_fact_event_id ON "marcin"."fact_events" (event_id);
Dbt run command can have more complex syntax. We may execute all depending objects with or without a tag or other constraints. Conditions may be joined with a comma (AND) or without a comma (OR) to get the exact set of conditions. Dbt docs example:
$ dbt run --select path:marts/finance,tag:nightly,config.materialized:table
Other commands, like dbt test, dbt source freshness or dbt snapshot are also generic SQL commands that are generated and executed in a similar way to the commands above. We do not see any rocket science or magic in dbt. We don't care about building slowly changing dimensions (SCD type2) or source validations. We already have it. We are allowed to manipulate the generic macros or build our own to fit exceptional models. However, the main idea remains, to build our project as simply as possible.
The most important fact is that all dbt features are managed and executed by a centralized engine. Dbt gives us common core features, that cover most of the engineering requirements and leave some place for developers' fantasies with Jinja macros or community snippets. This is what makes this tool unique. We as a team are empowered to use the same engineering standards and same coding techniques. In the very beginning, I thought it would constrain our work too much, but after a year of using it, the constraints appeared to be smart. The pipelines, with their simplicity, are almost error-proof and much easier to debug.
Within a project, all models use the same strategies and the same macros. I strongly recommend it for all projects that are supposed to have standardized architecture and standardized solutions. If our project or business forces us somehow to use different techniques for each model or pipeline, dbt can probably handle that, but it was not meant to work that way. It was meant to simplify and organize data transformations in a very convenient and efficient way. In the long term, this simplification brings benefits.